(Example 1) Help developers localize which lines of code are the most risky¶
Motivation¶
Traditionally, software defect predictions are proposed to predict which files are likely to be defective in the future. However, the proportion of critically-important defective lines are extremely low. Our prior studies found that the ratio of defective lines in a file is as low as 1%-3%. Thus, traditional file-level defect prediction models are still not practical to be used in practice. However, there exists no features at the line level. Thus, line-level defect prediction remains an extremely challenging problem.
Approach¶
To address this problem, we proposed to use the LIME’s model-agnostic technique[RSG16a] to explain the predictions of file-level defect prediction models. In particular, we first build file-level defect prediction models using textual features (i.e., bag of tokens that appear in a file) with a random forest classification technique. For each prediction, we apply LIME to understand the prediction. This approach allows us to identify which tokens and which lines contribute to the prediction of each file, which can be used to help developers localize which lines of code are the most risky.
Results¶
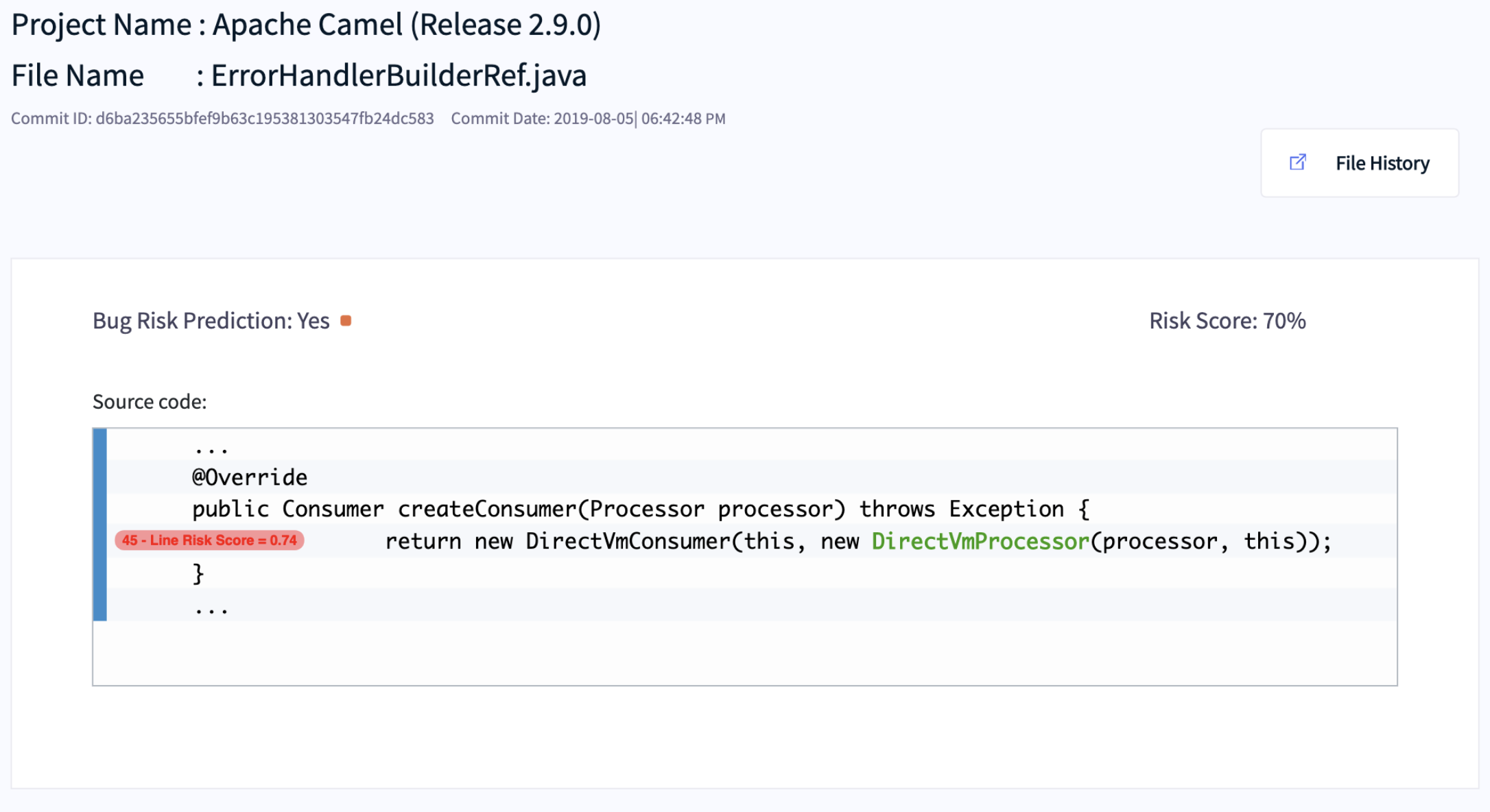
Fig. 9 An illustrative example of the use of LIME to identify which lines of code are the most risky.¶
Fig. 9 shows an example of the use of LIME to identify which lines of code are the most risky. The results show that this approach can correctly identify 61% of actual defective lines in a file, suggesting our approach could potentially help developers reduce SQA effort that need to be spent by 52% on clean lines, while accurately identifying 61% of actual defective lines.