(Step 1) Data Collection¶
Defect data preparation involves several key steps.
data-preparation provides an overview of defect data preparation steps.
First, one must extract issue reports, which describe defects, feature requests, or general maintenance tasks from an Issue Tracking System (ITS, e.g., JIRA).
Second, one must extract commit logs, code snapshots, and historical code changes that are recorded in a Version Control System (VCS, e.g., Git).
Third, one must extract software metrics of each module (e.g., size, and complexity) from the VCS.
To extract such software metrics, one must focus on development activities that occur prior to a release of interest that corresponds to the release branch of a studied system to ensure that activities that we study correspond to the development and maintenance of the official software releases.
Finally, one must identify and label modules as defective if they have been affected by code changes that address issue reports that were classified as defects after the software is released (i.e., post-release defects).
On the other hand, modules that are not changed to address any issue reports are labelled as clean.
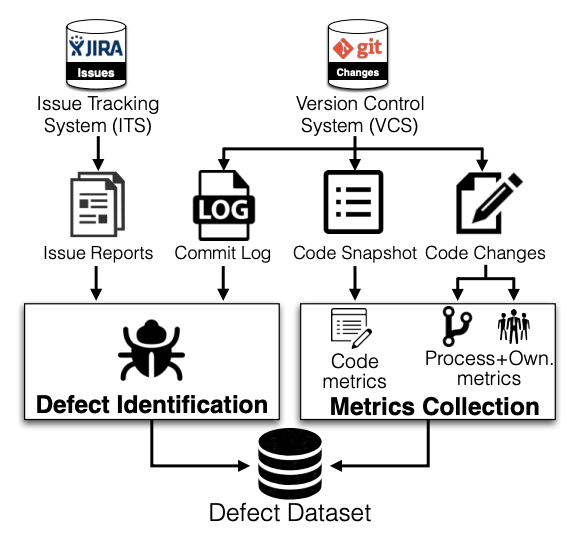
Fig. 4 An overview of defect data preparation steps.¶
Prior studies proposed several approaches to identify post-release defects, which we describe below.
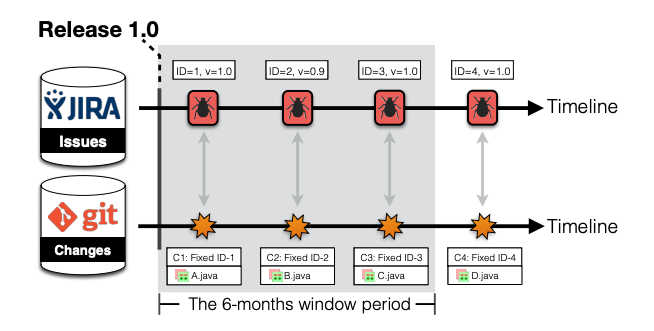
Fig. 5 An illustrative example of defect identification approaches, where ID indicates an issue report ID, v indicates affected release(s), C indicates a commit hash, indicates changed file(s), and the grey area indicates the 6-month period after a release of interest (i.e., Release 1.0).¶
The heuristic approach¶
Post-release defects are defined as modules that are changed to address a defect report within a post-release window period (e.g., 6 months) [DAmbrosLR10, DAmbrosLR12b, FPG03, KSA+13, ZPZ07, SliwerskiZZ05]. The commonly-used approach is to infer the relationship between the defect-fixing commits that are referred in commit logs and their associated defect reports. To identify defect-fixing commits, Fischer et al. [FPG03] are among the first to introduce a heuristic approach by using regular expression to search for specific keywords (e.g., fixed, bugs, defects) and issue IDs (e.g., 0-9) in commit logs after the release of interest.
To illustration, we use Fig. 5 to provide an example of defect identification of the heuristic approach for the release v1.0. First, the heuristic approach will apply a collection of regular expression patterns to search through the commit logs to find defect-fixing commits within a specific window period (i.e., 6 months). According to Fig. 5, the heuristic approach will label commits C1, C2, and C3 as defect-fixing commits, since their commit logs match with the collection of regular expression patterns that contain specific keywords and issue IDs. Then, the heuristic approach will label modules A.java, B.java, and C.java as defective modules. The remaining module (i.e., D.java) will be labelled as clean.
Unfortunately, such the heuristic approach has several limitations.
First, the heuristic approach assumes that all defect-fixing commits that are identified within the post-release window period of the release of interest (i.e., v1.0) are the defect-fixing commits that affect the release of interest.
However, data-preparation shows that the commit C2 was changed to address the issue report ID-2 where the release v0.9 was affected.
Thus, the module B.java that was labelled as defective by the heuristic approach is actually clean.
Second, the heuristic approach assumes that all defect-fixing commits that affect the release of interest (i.e., v1.0) only occur within the post-release window period of the release of interest.
Fig. 5 shows that the commit C4 was made to address the issue report ID-4 where the release v1.0 was affected, however the commit C4 was made outside the post-release window period.
Thus, the module D.java that was labelled as clean by the heuristic approach is actually defective.
The realistic approach¶
Recently, da Costa et al. [dCMS+17] suggest that the affected-release field in an ITS should be considered when identifying defect-introducing changes. To address the limitations of the heuristic approach, one should use the realistic approach, i.e., the use of the earliest affected release that is realistically estimated by a software development team for a given defect to generate post-release defects. The affected-release field in an ITS allows developers to record the actual releases of the system that are affected by a given defect. To identify defect-fixing commits, the realistic approach retrieves defect reports that affect a release of interest in the ITS. Since modern ITSs, like JIRA, provide traceable links between defect reports and code commits in VCS, the realistic approach can identify modules that are changed to address those defect reports. Then, the modules that are changed to address those defect reports are then identified as defective, otherwise clean.
To illustration, Fig. 5 shows that there are three issue reports (i.e., ID-1, ID-3, and ID-4) that affect the studied release v1.0. Then, commits C1, C3, and C4 which are linked to those three issue reports are identified as defect-fixing commits by the realistic approach. Finally, modules A.java, C.java, and D.java which are impacted by commits C1, C3, and C4 are labelled as defective modules.
Software Metrics¶
To prepare a defect dataset, we first extract metrics of software modules (e.g., size, complexity, process metrics) from a version control system (VCS). We focus on the development activity that occurs prior to a release that corresponds to the release branch of a studied system. With this strictly controlled setting, we ensure that changes that we study correspond to the development and maintenance of official software releases. Since modern issue tracking systems, like JIRA, often provide traceable links between issue reports (i.e., a report described defects or feature requests) and code changes, we can identify the modules that are changed to address a particular issue report. Finally, we label defective modules if they have been affected by a code change that addresses an issue report that is classified as a defect. Similar to prior studies [DAmbrosLR12a, KSA+13, ZPZ07], we define post-release defects as modules that are changed to address an issue report within the six-month period after the release date.
To understand the characteristics of defect-proneness, prior studies proposed a variety of metrics that are related to software quality. We provide a brief summary of software metrics below.
Code metrics describe the relationship between code properties and software quality. For example, in 1971, Akiyama [Aki71] is among the first research to show that the size of modules (e.g., lines of code) shares a relationship with defect-proneness. McCabe et al. [McC76] and Halstead also show that the high complexity of modules (e.g., the number of distinct operators and operands) are likely to be more defective. Chidamber and Kemerer [CK94] also propose CK metrics suites, a set of six metrics that describe the structure of a class (e.g., the number of methods defined in a class), that may share a relationship with defect-proneness. An independent evaluation by Basili et al. [BBM96] and Gyimothy et al. [GyimothyFS05] confirms that the CK metrics suites can be effectively used as software quality indicators. An in-depth investigation on the size-defect relationship by Syer [SNAH14] shows that defect density has an inverted “U” shaped pattern (i.e., defect density increases in smaller files, peaks in the largest small-sized files/smallest medium-sized files, then decreases in medium and larger files). Such code metrics are typically extracted from a code snapshot at a release using various available static analysis tools (e.g., SLOCcount tool, Understand tool , the mccabe python package, and the radon python package).
Process metrics describe the relationship between change activities during software development process and software quality. Prior work has shown that historical software development process can be used to describe the characteristics of defect-proneness. For example, Graves [GKMS00] find that the software defects may still exist in modules that were recently defective. Nagappan and Ball [NB05b, NB07] find that modules that have undergone a lot of change are likely to be more defective. Hassan [Has09] find that modules with a volatile change process, where changes are spread amongst several files are likely defective. Hassan and Holt [aEHH05] find that modules that are recently changed are more likely to be defective. Zimmermann and Nagappan [ZN08, ZNG+09, ZPZ07] find that program dependency graphs share a relationship with software quality. Zimmermann et al. [ZPZ07] find that the number of defects that were reported in the last six months before release for a module shares a relationship with software quality. Such process metrics are typically extracted using code changes that are stored in VCSs.
Organization metrics describe the relationship between organization structure and software quality [NMB08]. For example, Graves et al. [GKMS00] find that modules that are changed by a large number of developers are likely to be more defective. Despite of the organization structure, prior studies have shown that code ownership shares a relationship with software quality. Thus, we focus on the two dimensions for an approximation of code ownership. First, authoring activity has been widely used to approximate code ownership. For example, Mockus and Herbslerb [MH02] identify developers who responsible for a module using the number of tasks that a developer has completed. Furthermore, Bird et al. [BMG11] find that modules that are written by many experts are less likely to be defect-prone. Second, reviewing activity has been also used to approximate code ownership. For example, Thongtanunam [TMHI16] find that reviewing expertise also shares a relationship with defect-proneness (e.g., modules that are reviewed by experts are less likely to be defect-prone).
Note
Parts of this chapter have been published by Suraj Yatish, Jirayus Jiarpakdee, Patanamon Thongtanunam, Chakkrit Tantithamthavorn: Mining software defects: should we consider affected releases? ICSE 2019: 654-665.
Suggested Readings¶
[1] Christian Bird, Nachiappan Nagappan, Brendan Murphy, Harald C. Gall, Premkumar T. Devanbu: Don’t touch my code!: examining the effects of ownership on software quality. SIGSOFT FSE 2011: 4-14.
[2] Foyzur Rahman, Premkumar T. Devanbu: How, and why, process metrics are better. ICSE 2013: 432-441.
[3] Nachiappan Nagappan, Thomas Ball: Use of relative code churn measures to predict system defect density. ICSE 2005: 284-292.
[4] Patanamon Thongtanunam, Shane McIntosh, Ahmed E. Hassan, Hajimu Iida: Revisiting code ownership and its relationship with software quality in the scope of modern code review. ICSE 2016: 1039-1050.
[5] Thomas Zimmermann, Rahul Premraj, Andreas Zeller: Predicting defects for Eclipse. PROMISE 2007.