(Example 2) Help developers understand why a file is predicted as defective¶
Motivation¶
Traditionally, the predictions of defect models can help developers prioritize which files are the most risky. However, developers do not understand why a file is predicted as defective, leading to a lack of trust in the predictions and hindering the adoption of defect prediction models in practice. Thus, a lack of explainability of defect prediction models remains an extremely challenging problem.
Approach¶
To address this problem, we proposed to use a model-agnostic technique called LIME[RSG16a] to explain the predictions of file-level defect prediction models. In particular, we first build file-level defect prediction models that are trained using traditional software features (e.g., lines of code, code complexity, the number of developers who edited a file) with a random forest classification technique. For each prediction, we apply LIME to understand the prediction. This approach allows us to identify which features contribute to the prediction of each file. This will help developers understand why a file is predicted as defective.
Results¶
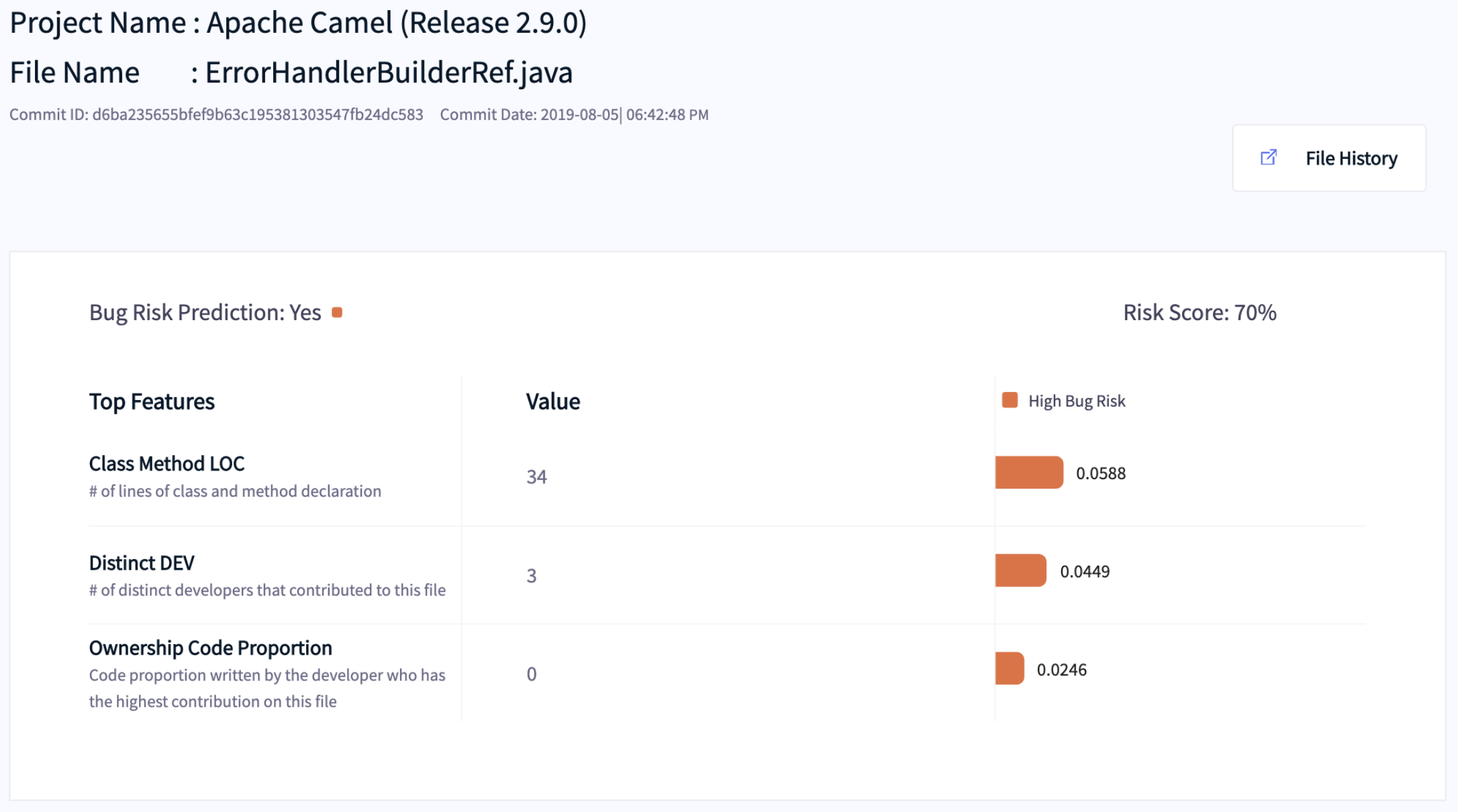
Fig. 10 An example of a visual explanation generated by LIME.¶
Fig. 10 presents an example of a visual explanation generated by LIME to understand why a file is predicted as defective. According to this visual explanation, this file is predicted as defective with a risk score of 70%. The top-3 important factors that support this prediction are (1) the high number of class and method declaration lines, (2) the high number of distinct developers that contributed to the file, and (3) the low proportion of code ownership. Thus, to mitigate the risk of having defects for this file, developers should consider decreasing the number of class and method declaration lines, reducing the number of distinct developers, and increasing the proportion of code ownership.