Defect Prediction¶
Defect prediction models have been proposed to predict the most risky areas of source code that are likely to have post-release defects [MGF07] [NZZ+10] [DAmbrosLR10] [TMHM18] [TMHM16a] [WLT16] [WLNT18]. A defect prediction model is a classification model that estimates the likelihood that a file will have post-release defects. One of the main purposes is to help practitioners effectively spend their limited SQA resources on the most risky areas of code in a cost-effective manner. s
The modelling pipeline of defect prediction models¶
The predictive accuracy of the defect prediction model heavily relies on the modelling pipelines of defect prediction models [TMH+15][TMHM16b][TH18][MS19][GMH15][AM18][Tan16]. To accurately predicting defective areas of code, prior studies conducted a comprehensive evaluation to identify the best technique of the modelling pipelines for defect models. For example, feature selection techniques [GMH17][JTT18b][JTT20a], collinearity analysis [JTT18b][JTIM16][JTH19], class rebalancing techniques [THM19], classification techniques [GMH15], parameter optimization [TMHM16a][FMS16][TMHM18][AM18], model validation [TMHM17], and model interpretation [JTH19][JTDG20a]. Despite the recent advances in the modelling pipelines for defect prediction models, the cost-effectiveness of the SQA resource prioritization still relies on the granularity of the predictions.
The granularity levels of defect predictions models¶
The cost-effectiveness of the SQA resource prioritization heavily relies on the granularity levels of defect prediction. Prior studies argued that prioritizing software modules at the finer granularity is more cost-effective [PPB19] [KMM+10] [HMK12]. For example, Kamei et al. [KMM+10] found that the file-level defect prediction is more effective than the package-level defect prediction. Hata et al. [HMK12] found that the method-level defect prediction is more effective than file-level defect prediction. Defect models at various granularity levels have been proposed, e.g., packages [KMM+10], components [TMHI16], modules [KMM+07], files [KMM+10] [MK10], methods [HMK12]. However, developers could still waste an SQA effort on manually identifying the most risky lines, since the current prediction granularity is still perceived as coarse-grained [WXH+18]. Hence, the line-level defect prediction should be beneficial to SQA teams to spend optimal effort on identifying and analyzing defects.
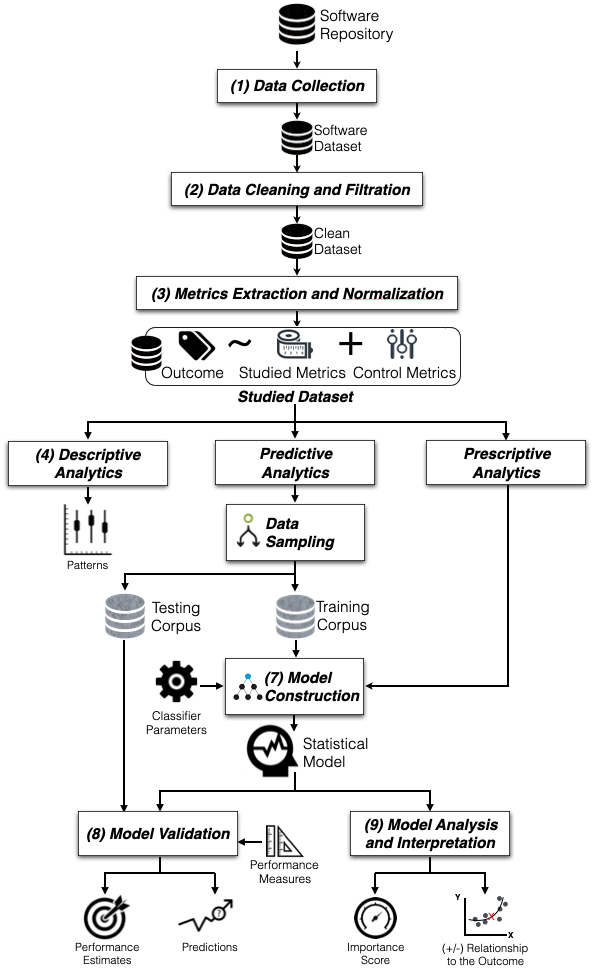
Fig. 3 An overview process of defect prediction models.¶